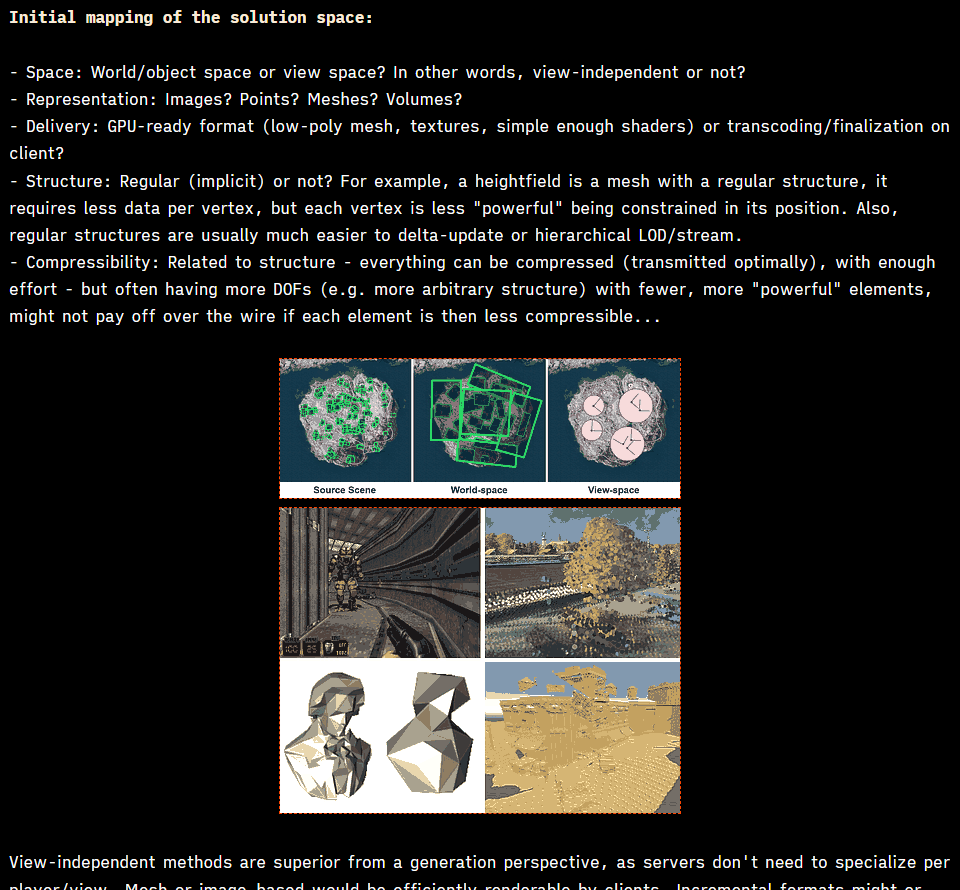
Read the article here: https://c0de517e.com/013_web.htm

This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: https://c0de517e.com/013_web.htm
This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: https://c0de517e.com/012_peak_tech.htm

This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: https://c0de517e.com/011_portals.htm

This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: https://c0de517e.com/009_website_joy.htm
This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: Exploring the design space of "remote scene approximation". (c0de517e.com)
This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.